All About Character Encodings
November 8, 2004
by Kerry Thompson
"Yo, guru!" I looked up to see the guy a couple cubicles over prairie-dogging, trying to get my attention. I think they call me "guru" because I'm too old to be called "dude," not from the feeling of awe I think is my due. "What's the ASCII code for the German u-umlaut?"
I was tempted to say "none," which would have been, technically, the correct answer. Instead, I opted to be nice for once, and told him "Lower case? 252, decimal."
I could have spent time explaining the difference between ASCII, ANSI, ISO 8859, and the Apple Standard Roman character set. Perhaps I could have thrown in some tidbits about so-called double-byte characters used in Chinese, Japanese, and Korean. I love to see people's eyes glaze over.
Instead, I decided, with a little prompting, to put that information into this article, in the hope that it will reach some people who can actually use the information.
The Basics
You probably already know this, but we have to start someplace. Letters, numbers, punctuation, ideograms, syllabaries -- the building blocks of written language -- are represented in a computer by numeric codes. Pretty much everybody agrees that, when the computer sees a code of 101 (decimal), that it represents a lower-case 'e'. We don't all agree what 252 represents, and therein lies the rub.
ASCII vs. ANSI
We commonly refer to character encoding as a letter's "ASCII value", when we really mean "ANSI value." A lot of the time that's sufficient, but in fact the ASCII standard is pretty much obsolete.
ASCII (American Standard Code for Information Interchange) is a 7-bit standard that has been around for decades, with its beginnings the late 1950s (its current incarnation dates from 1968). It defines 128 different characters, which is more than enough for English: upper- and lower-case letters, punctuation, numerals, control codes (remember control-c?), and non-printing codes such as tab, return, and backspace.
Over the past couple of decades, though, computing has become world-wide, and the old English-centric ASCII system just wasn't up to handling German, French, Spanish, and Portuguese, not to mention Turkish, Arabic, and Chinese. There are national variants of ASCII, which enjoyed a brief popularity in the 1980s. However, an 8-bit encoding system was developed by the American National Standard Institute (ANSI) in the late 1980s, and it included all the characters needed for most Western European Languages. Microsoft's adoption of the ANSI standard for Windows 3.1 gave it the momentum to become the dominant standard, and today it is the de facto standard for Western European languages.
You may have noticed that I haven't mentioned the word "Macintosh" yet. That's because this article is going to be (appallingly, for some) Windows-centric. That's not because of any prejudice against the Mac; I have been using Macintosh computers for years, and the Apple II before that, and the Apple before that. I love the Mac, and use both Mac and Windows computers every day.
I decided to concentrate on Windows because space for this article is limited, and I had to choose one or the other. And, at the end of the day, it doesn't matter a whole lot, because the concepts apply equally to both platforms. The details differ -- Macintosh encodes the extended character set (mostly accented and special characters) somewhat differently from Windows, but the basics are the same. There is a wealth of information on the Web, especially on Apple's Web site, to fill in the missing details.
What About Turkey, Greece, and Russia?
Computing has spread well beyond the U.S. and Western Europe, so a need quickly developed for a standard for encoding other languages. The International Standards Organization (ISO) provided the answer in its ISO 8859 standard.
I know what you're probably thinking. There are hundreds of written languages in the world, from Afrikaans to Vietnamese. If they're all single-byte languages, how can they be covered by a single standard? The answer is, ISO 8859 is really several standards -- fifteen now, and growing.
The most commonly used ISO 8859 standard is ISO 8859-1, or Latin 1. It covers most Western European languages, and then some: Albanian, Basque, Catalan, Danish, Dutch (partial), English, Faeroese, Finnish (partial), French (partial), German, Icelandic, Irish, Italian, Norwegian, Portuguese, Rhaeto-Romanic, Scottish, Spanish, Kurdish, Swedish, Afrikaans, and Swahili.
Following is a summary of the other ISO 8859 standards:
- ISO 8859-2 (Latin-2 or Central European) -- Central and Eastern European languages that use a Roman alphabet, including Polish, Czech, Slovak, Slovenian, and Hungarian.
- ISO 8859-3 (Latin-3 or South European) -- Turkish, Maltese, and Esperanto; largely superseded by ISO 8859-9 for Turkish and Unicode for Esperanto.
- ISO 8859-4 (Latin-4 or North European) -- Estonian, Latvian, Lithuanian, Greenlandic, and Sami.
- ISO 8859-5 (Cyrillic) -- Covers most East European languages that use a Cyrillic alphabet, including Russian, Ukrainian, and Belarusian.
- ISO 8859-6 (Arabic) -- Covers the most common Arabic glyphs, although not nearly all of them.
- ISO 8859-7 (Greek) -- Modern Greek
- ISO 8859-8 (Hebrew) -- The modern Hebrew alphabet as used in Israel.
- ISO 8859-9 (Latin-5 or Turkish) -- Largely the same as ISO 8859-1, replacing the rarely used Icelandic letters with Turkish ones.
- ISO 8859-10 (Latin-6 or Nordic) -- a rearrangement of Latin-4. Considered more useful for Nordic languages.
- ISO 8859-11 (Thai) -- Not a complete representation of Thai, but covers most of the glyphs.
- ISO 8859-12 -- was supposed to be Latin-7 and cover Celtic, but this draft was rejected.
- ISO 8859-13 (Latin-7 or Baltic Rim) -- Added some glyphs for Baltic languages which were missing from Latin-4 and Latin-6.
- ISO 8859-14 (Latin-8 or Celtic) -- Mostly a rearrangement of the ISO-8859-12 draft. Covers Celtic languages like Gaelic and the Breton language.
- ISO 8859-15 (Latin-9) -- a revision of 8859-1 that removes some little-used symbols, replacing them with the Euro symbol
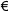 and the letters
and the letters  , which completes the coverage of French and Finnish.
, which completes the coverage of French and Finnish. - ISO 8859-16 (Latin-10 or South-Eastern European) -- In development, intended for Albanian, Croatian, Hungarian, Italian, Polish, Romanian and Slovenian, but also Finnish, French, German and Irish Gaelic.
Using Other Character Sets: Code Pages
English Windows is designed -- are you ready -- for English. That doesn't mean it doesn't support other languages, though. It just means we have to work a little harder to utilize them.
Output is fairly easy, especially for Latin-1 languages (remember, that's most of the Western European languages, including English.) Here is some text copied from a German French Horn manufacturer's Web site, http://www.ricco-kuehn.de/index.htm:

I simply used the same Times New Roman font I've been using for English. Since it is an ANSI font, it has all the German characters we need, including 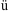 . It would have worked with French, Italian, Portuguese, or any other ISO 8859-1 language.
. It would have worked with French, Italian, Portuguese, or any other ISO 8859-1 language.
But what about Russian? Could I go to the Pravda Web page and copy something from a Russian-language Forbes article? Check it out:
 .
.
I have no idea what that means, but apparently I can use Cyrillic text on English Windows. I can even use my dependable Times New Roman font. So what's going on here? Didn't we say that Russian used a different encoding, ISO 8859-5?
It does. We were fortunate, because the version of Times New Roman I have on my system supports code page 1251, where the Cyrillic alphabet lives, in addition to Latin-1's code page 1252.
The term "code page" can be confusing because it is really just another way of referring to the character encoding. Essentially, code page 1251 and Cyrillic encoding are synonymous. You could imagine a font as a stack, something like this:
| Code Page | ISO 8859 |
|---|---|
| 1250 | 8859-2 (Central Europe) |
| 1251 | 8859-5 (Cyrillic) |
| 1252 | 8859-1 (Latin 1) |
| 1253 | 8859-7 (Greek) |
| 1254 | 8859-9 (Turkish) |
| 1255 | 8859-8 (Hebrew) |
| 1256 | 8859-6 (Arabic) |
| 1257 | 8859-4 (Baltic) |
| 1258 | VISCII (Vietnamese) |
| 874 | 8859-11 (Thai) |
Font publishers often include several national character sets within a single font -- it's simpler if you can just install Arial, and have Roman 1 on an English system, Cyrillic on a Russian system, and Greek on a Greek system.
Not all programs support code pages the same way, though. Macromedia's Director, for example, has rather spotty code page support. It will display Russian on an English system -- but dependably only if you embed a Russian font in your movie. Also, sending text information between Flash, which is Unicode-enabled, and Director, which is not, needs special care. Communications between Director and Flash are further complicated by the fact that both are cross-platform Macintosh and Windows, but the two systems encode high-ANSI characters differently.
Asian and Double-byte Languages
You may have noticed that we have so far neglected a lot of languages, especially Asian languages. Chinese, Japanese, and Korean are special cases that we will cover shortly, but what about Tibetan, Lao, and other Asian languages?
A few years ago I was a contributor to the Radio Free Asia Web Site, which had text in Vietnamese, Khmer, Laotian, Burmese, and Tibetan, none of which were (or are) covered by ISO 8859. These are all single-byte languages, and codifying them remains a work in progress. You can find Tibetan fonts, and by and large they agree on code usage, but a standard is hampered partly by low per-capita computer usage, and partly because scholars don't agree on some of the basics of the written language, like standardized spelling.
Currently, those languages are likely to be covered by Unicode, a standard that has been developing for over two decades. Unicode is outside the scope of this article, but it is basically a double-byte standard designed to offer standardized encodings for virtually every written human language (and purportedly for some non-human languages like Klingon, which, for some reason, has been excluded from the Unicode specification).
Chinese (simplified and traditional), Japanese, and Korean, often referred to as CCJK, have too many characters for any single-byte encoding, so they are commonly referred to as "double-byte" languages. Actually, that is a misnomer, because they are a mixture of single- and double-byte codes. Most encodings of those languages have ASCII or ANSI characters as single-byte characters, and the rest of the characters are double-byte. They should more properly be called "multi-byte" languages, but nobody but a purist (like me) will be bothered if you call them double-byte.
To understand multibyte encodings, it helps to understand a little about the languages. We'll begin with Chinese, because the concepts carry over to the other multibyte languages. Also, I know more about Chinese than either of the others. I deny allegations that I chose Chinese because my wife is Chinese (actually, I don't deny that she is Chinese, only... well, never mind, let's just get on with it.)
Chinese
Chinese, as most people know, uses ideograms -- characters that represent a concept such as day, person, happy, or spoon, but have no inherent phonetic characteristics.
Actually, ideograms are not too hard a concept to grasp, because we use them in virtually every Western language. Consider this: 42. Those two characters represent a concept that means the same to you whether you speak English, Chinese, or Arabic, which happens to be where they originated. What's more, each of the two numerals can stand on its own, with a somewhat different meaning.
There is nothing inherently phonetic about them: you can pronounce them forty-two, zwei und vierzig, or si-shi er, and they convey exactly the same meaning. Now, extend that concept to encompass an entire human language, and you understand ideograms.
Clearly, there are more than 256 concepts in any human language. That's why Chinese can't use a single-byte encoding. Nobody really knows how many Chinese characters there are, but you need to know about 3,000 to read a newspaper, and a scholar may know 10,000 characters. With two bytes, we can represent over 65,000 characters -- sufficient for Chinese.
No Chinese font can reasonably expect to contain every possible character a Chinese writer will need, so Chinese encoding systems specify locations for custom characters. People's names are often written with unique characters; occasionally new characters are invented for new concepts; and there are some characters that are rarely used, like the 15th-century word for county magistrate in Yunnan province.
Chinese is further complicated by the fact that there are two methods of writing Chinese, alluded to above -- simplified and traditional. Traditional characters, or "complicated-body characters" as they are called in Chinese, are used in Hong Kong, Taiwan, and by most overseas Chinese. Simplified characters, popularized by Mao Ze-Dong's push to bring literacy to the masses, are widely used in mainland China, and in Singapore. Increasingly, they are used overseas as a new generation of Chinese speakers emigrates.
Simplified and traditional characters have nothing to do with pronunciation. If you read Chinese characters, you can read Chinese, regardless of which Chinese language you speak -- Mandarin, Cantonese, Shanghainese, Chongqing-hua, or any of the dozens, and probably hundreds, of distinct Chinese languages and dialects. If you think about our Western ideograms (numerals), you will realize we do the same thing. 2^8 = 256 means the same to everybody, no matter what language they speak.
Traditional and simplified characters do, however, have an impact on encoding. The Big-5 encoding system was originally developed for traditional Chinese, and is the basis of Traditional Chinese Windows as used in Taiwan. GB encoding was developed for simplified characters, and is the basis of Simplified Chinese Windows as used on the mainland. Nowadays, there are Big-5 encoded simplified Chinese fonts, and GB-encoded traditional character fonts, but the basic distinction remains.
Some Chinese systems allow you to convert from traditional to simplified characters automatically. That's relatively straightforward -- you can reliably map traditional characters to simplified characters. However, because of the way Chinese was simplified, you often can't automatically convert simplified to traditional.
Chinese characters were simplified in two ways. Some characters are written with a reduced number of strokes -- for example, the "speech" character was simplified from 7 strokes to 2. Other characters were simply combined. For example, the Mandarin words for "empress" and "behind" are pronounced exactly the same, so one of the traditional characters was dropped, and both are represented by one character in simplified Chinese.
Japanese
Japanese uses one of the most complex writing systems on Earth, with no fewer than four character sets: kanji, hiragana, katakana, and romaji, all of which can be freely mixed in Japanese text.
Kanji requires little explanation: they are Chinese characters. In fact, the very word "Kanji" means, literally, "Chinese Character." Japanese uses about 6,000 Chinese characters -- 2,000 in everyday life -- and by and large they have the same, or similar, meanings as they do in Chinese. In fact, they usually have a "Chinese" pronunciation in addition to one or more Japanese pronunciations. For example, the character for mountain, 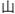 , can be read with the "Japanese" pronunciation 'yama', or 'san', similar to the Chinese pronunciation 'shan'.
, can be read with the "Japanese" pronunciation 'yama', or 'san', similar to the Chinese pronunciation 'shan'.
Hiragana and katakana, collectively know as kana, are phonetic writing systems. However, they are not alphabetic in the way Westerners are used to. They don't represent vowels and consonants. Rather, each kana character represents one syllable: for example, 'a', 'mi', or 'to'. There are ways of modifying some of the characters -- for example, making 'sa' into 'za', or 'ki' into 'kyo,' but all sounds in the Japanese language can be represented by one of the 46 hiragana or katakana characters.
Hiragana and katakana characters are phonetic duplicates of each other. That is, for every hiragana character, there is a corresponding katakana character, pronounced exactly the same. With some exceptions, hiragana is used for native Japanese words, and katakana is used for "loan words" -- words imported from other languages, usually English -- of which there are many.
The other character set the Japanese language uses is romaji, or Roman characters. These are the same letters used in Western European languages -- basically, the same letters you have been reading for the past fifteen minutes or so. Romaji are usually used to spell a foreign name or word.
There are three popular Japanese character encodings, all based on the "Japanese Industrial Standard," or JIS. When people speak of JIS encoding, they are referring to the ISO standard 2022-JP, which is actually a 7-bit code sometimes used for transmitting characters.
More commonly used now is EUC, or Extended UNIX Coding, which is a multibyte system utilizing 8-bit bytes, and is pretty much the standard on the Internet. The other system, Shift-JIS, was developed by Microsoft for Japanese versions of their OS and software, and is the encoding used for things like files and applications.
Korean
Korean text, or Hangul, is probably the easiest to understand. Hangul characters, like Japanese kana, represent syllables. Unlike Japanese kana, though, Hangul characters are formed with strokes representing vowels and consonants, and combined into syllabic blocks called jamo. You should note that, even though the basic Hangul strokes represent individual sounds, they are not combined to form words, but syllables that are then combined to form words.
The Hangul system has been used in Korea for over 500 years, since its invention in 1443. Before that, the Korean language was written with Chinese characters, and you will still find Chinese characters in Korean text, though it is becoming less common. The Korean Standard Hangul Coding Scheme for Communications (KS5601) includes nearly 5,000 Chinese characters in addition to over 2,300 Hangul characters.
Tying it all together
Representing the world's hundreds of languages on computers is a daunting and complex task. This article has covered the basics of a few languages, on a single system, Windows. We haven't addressed input or Unicode, either of which would need an entire article, or book, to cover in any depth.
However, this is a start, and hopefully will provide a jumping-off point for people to explore the subject in more depth.
Then maybe your co-workers will call you guru -- and mean it.
Copyright 1997-2026, Director Online. Article content copyright by respective authors.